
#+SETUPFILE: ~/Dropbox/Doc/Org_Templates/level-1.org
简介
顾名思义, pNFS(Parallel NFS) 是 NFS 的并行实现, 它弥补了传统 NFS 协议在设计 上的不足, 把传统 NFS 的性能提高了好几个数量级.
可以通过”布局”, 向上提供基于文件, 对象, 甚至是块设备的访问方式.
传统 NFS 遇到的挑战
下图是传统 NFS 协议的简单架构图: 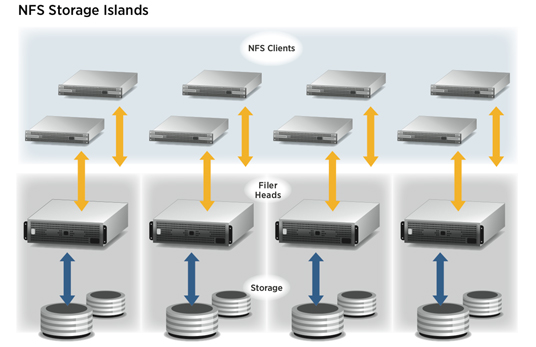
从图中可以看出, NFS 文件的读写操作和元数据的相关操作, 都需要从客户机传到 NFS 服务器, NFS 服务器再执行最终的所有 I/O 操作(文件读写, 元数据修改).
这样就会有一个问题, 因为 NFS 服务器能同时接受多个客户端的请求, 当大量的客户端 需要同时对 NFS 上的文件进行 I/O 的时候, 很明显, NFS 服务器就成为了系统瓶颈, 使得系统性能大大降低.
pNFS 就是为了从根本消除这个系统瓶颈而出现的.
pNFS 的架构
下图描述的是 pNFS 的简单架构图: 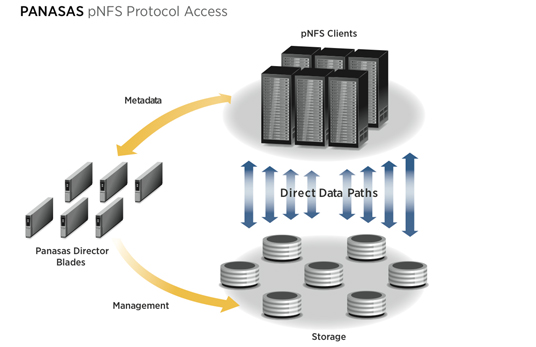
从上图中可以看到, 客户端直接对物理存储进行读写, 数据流不需要经过 pNFS 服务器. pNFS 服务器的作用, 仅仅是用来控制文件的元数据和协调多个客户端的快速访问.
服务器通过一个叫 “布局” 的东西来向客户端描述文件元数据, 当客户端想要访问一个 文件的时候, 首先会像服务器发送一个请求, 获取布局和文件的授权, 得知这些信息 之后, 就可以直接向存储设备进行数据读写了, 这个时候完全不需要 pNFS 服务器的 干预. 布局可以缓存到每个客户机, 使得进一步提升了性能.
pNFS 的优势
使用传统的 NFS, 数据的每个比特都要通过 NFS 服务器, 导致性能很低. 如果使用 pNFS, 就把 NFS 服务器从主数据通路中移出来了, 这使得客户端能够自由快速地存取 数据, 完全消除了 nfs 的系统瓶颈, 多个客户端同时访问服务器的性能得到很大的提高, 且系统容量能够容易扩展而不影响总性能.
pNFS 的不足
纵观各路网络/分布式文件系统(e.g. ceph, gfs 等), 元数据服务器(MDS)都是 一个很大的问题, 各种文件系统使用了不同的手段来消除其带来的瓶颈. 比如 GlusterFS 破天荒的消除了 MDS, ceph 把 MDS 也分布式了. 但是在 pNFS 上还没有看到过 这方面的讨论, 在大量小文件的存储系统上可能带来一些问题(FIXME if I am wrong).
进一步的分析有待讨论.
pNFS 的现状和未来
pNFS 已经成为 NFS 4.1 标准的一个扩展, 并且客户端的代码已经合并到 kernel 2.6.37 的版本中.
在 linux 发行商方面, RedHat 已经宣布 RHEL 6.4 支持文件布局的 pnfs 客户端了.
据说曾经(?)世界上最快的超级计算机, 称号为 Roadrunner 的机器使用的并行文件系统, 就是以 pNFS 标准为核心构建的, 虽然我不太认同, 但是很多人认为该技术可能引导未来并行 存储甚至是未来存储技术的主导.




