
#+SETUPFILE: ~/Dropbox/Doc/Org_Templates/level-1.org
介绍
Ceph 是新一代的分布式文件系统, 具有高扩展, 高可靠性, 高性能的特点. 它采用多个 多个元数据 + 多个存储节点 + 多个监控节点的架构, 解决单点故障的问题.
架构简介
如图, ceph 的后端是 RADOS, 一个对象存储系统. 通过 rados, 提供了以下接口:
- 类似于 amazon S3 的对象存储系统
- Block 设备接口
- 文件系统接口, 兼容 POSIX
#+ATTR_HTML: width="800px"
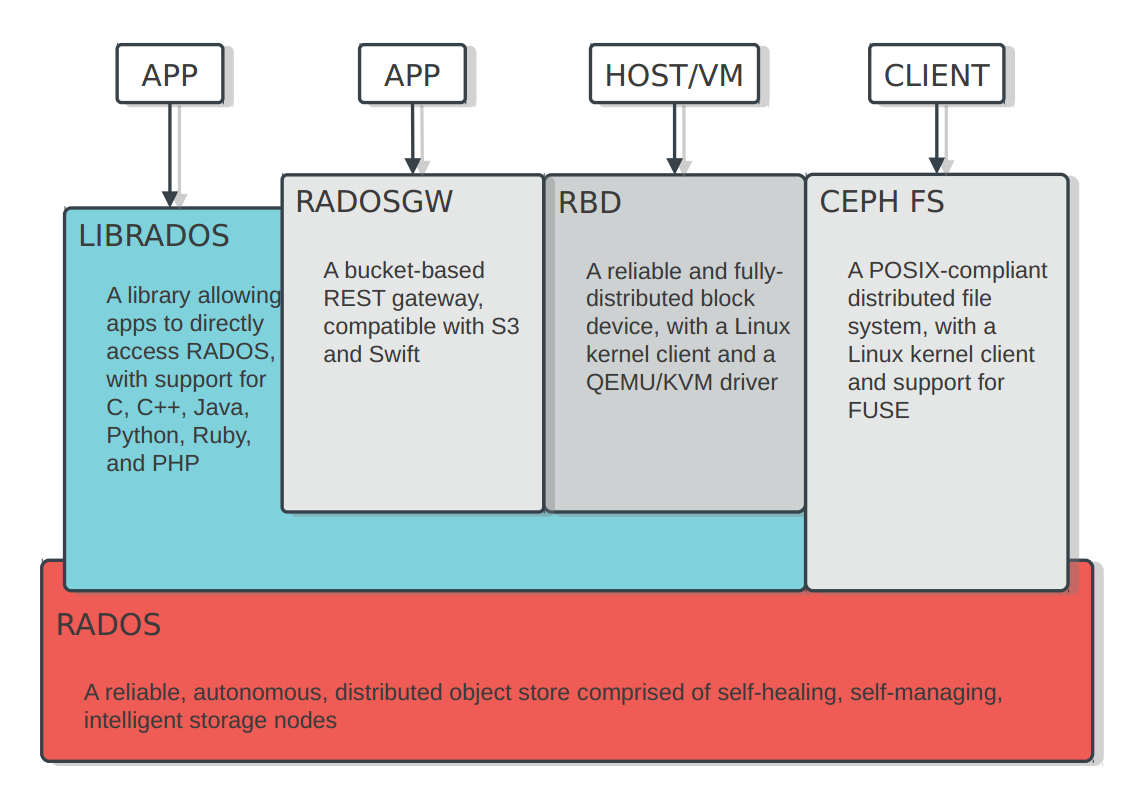
组件简介
ceph 主要由以下组件:
- osd: Object Storage Device, 负责提供存储资源
- monitor: 维护整个 ceph 集群的状态
- mds: 保存 cephfs 的元数据, 非必须, 只有 cephfs 接口需要此模块
- rados gateway: 提供 REST 接口, 兼容 S3 和 Swift 的 API
搭建环境准备
准备了三台机器, 每台机器有两个磁盘(vda, vdb), 初始搭建用 ceph1 作为 mon, ceph2, ceph3 作为 osd, osd mon, osd 的扩展之后完成
| Hostname | IP Address | Role |
|---|---|---|
| ceph1 | 192.168.176.30 | mon,admin |
| ceph2 | 192.168.176.31 | osd |
| ceph3 | 192.168.176.32 | osd |
- 修改三台节点的 hosts 文件, 使得彼此可见, 在每一个节点 的/etc/hosts 中, 加入
192.168.176.30 ceph1
192.168.176.31 ceph2
192.168.176.32 ceph3
- 把 admin 节点(ceph1) 的 ssh 密钥拷贝到其他节点, 使得 ceph1 可以无密码访问其他节点
# ssh-keygen
# ssh-copy-id ceph1
# ssh-copy-id ceph2
# ssh-copy-id ceph3
- 在 admin node(ceph1) 上, 设置 ceph 的软件源仓库
# wget -q -O- 'https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc' | \
apt-key add -
# echo deb http://ceph.com/packages/ceph-extras/debian $(lsb_release -sc) main | \
tee /etc/apt/sources.list.d/ceph-extras.list
# CODENAME 是 lsb_release -sc 得到的值
# apt-add-repository 'deb http://ceph.com/debian-emperor/ {CODENAME} main'
# apt-get update && apt-get install ceph-deploy
部署
部署工作是在 admin node 上完成的.
# 1. 创建一个工作目录
# mkdir -p ~/my-cluster && cd ~/my-cluster
# 2. 创建一个集群, 默认集群名为 ceph, 默认 monitor 为 ceph1
# ceph-deploy new ceph1
# 3. 在所有节点上安装 ceph 软件包, 此操作将在所有节点上执行以下操作, 1) 添加 ceph
# 的软件源, 2) 更新软件源数据库, 安装 ceph ceph-mds ceph-common ceph-fs-common
# 和 gdisk 软件包
# ceph-deploy install ceph1 ceph2 ceph3
# 4. 创建 mon, 这里选择 ceph1 作为 monitor 节点, 大概的流程如下:
# 1) 把 ceph.conf 文件复制到 ceph1:/etc/ceph
# 2) 在 ceph1 中创建 ceph1:/var/lib/ceph/mon/ceph-ceph1 并把 ceph.mon.keyring
# 复制到 ceph1:/var/lib/ceph/tmp/ceph-ceph1.mon.keyring
# 3) 在 ceph1 中使用以下命令初始化 monitor data:
# ceph-mon --cluster ceph --mkfs -i ceph1 --keyring /var/lib/ceph/tmp/ceph-ceph1.mon.keyring
# 4) 在 ceph1 中运行 initctl emit ceph-mon cluster=ceph id=ceph1 启动 ceph-mon
# 或者使用 service ceph -c /etc/ceph/ceph.conf start mon.ceph1
# 5) 在 ceph1 中用 ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.ceph1.asok mon_status
# 检查 ceph1 的 mon 状态, 如果有错误, 报告之
# ceph-deploy mon create ceph1
# 5. 复制远程 node 上的密钥复制到当前文件夹, 包括:
# ceph.client.admin.keyring ==> ceph.client.admin.keyring
# /var/lib/ceph/mon/ceph-ceph1/keyring ==> ceph.mon.keyring
# /var/lib/ceph/bootstrap-osd/ceph.keyring ==> ceph.bootstrap-osd.keyring
# /var/lib/ceph/bootstrap-mds/ceph.keyring ==> ceph.bootstrap-mds.keyring
# ceph-deploy gatherkeys ceph1
# 6. 增加 osd
# prepare 主要步骤:
# 1) push 配置文件 到 ceph{2,3}:/etc/ceph/ceph.conf
# 2) push ceph.bootstrap-osd.keyring 复制到 ceph{2,3}:/var/lib/ceph/bootstrap-osd/ceph.keyring
# 3) udevadm trigger --subsystem-match=block --action=add
# 4) ceph-disk-prepare --fs-type xfs --cluster ceph -- /dev/vdb ==> 创建分区, 格式化 等
# activate 步骤:
# ceph-disk-activate --mark-init upstart --mount /dev/vdb ==> 挂载 ceph 分区, 使用以下命令启动
# initctl emit --no-wait -- ceph-osd cluster=ceph id=0
# ceph-deploy osd prepare ceph2:/dev/vdb ceph3:/dev/vdb
# ceph-deploy osd activate ceph2:/dev/vdb ceph3:/dev/vdb
# ceph osd tree # 查看 osd 的状态
# id weight type name up/down reweight
-1 0.3 root default
-2 0.09999 host ceph2
0 0.09999 osd.0 up 1
-3 0.09999 host ceph3
1 0.09999 osd.1 up 1
# 7. 复制 admin 密钥到其他节点
# 复制 ceph.conf, ceph.client.admin.keyring 到 ceph{1,2,3}:/etc/ceph
# ceph-deploy admin ceph1 ceph2 ceph3
# 8. 查看部署状态
# ceph health
HEALTH_OK ==> that's all
添加新的 osd
这里准备把 ceph1 变为 一个新的 osd
# 根据上面的介绍, 新增一个 osd 很简单
# ceph-deploy osd prepare ceph1:/dev/vdb
# ceph-deploy osd activate ceph1:/dev/vdb
# ceph osd tree # 查看状态
# id weight type name up/down reweight
-1 0.3 root default
-2 0.09999 host ceph2
0 0.09999 osd.0 up 1
-3 0.09999 host ceph3
1 0.09999 osd.1 up 1
-4 0.09999 host ceph1
2 0.09999 osd.2 up 1
添加新的 mon
为了 monitor 的高可用, 一般部署的时候推荐设置多个 monitor, 这里把 ceph2 和 ceph3 也变为 monitor.
# 1. ceph2, ceph3 不在 mon_initial_members 中, 这里把 ceph{2,3} 也加入配置文件中
# 顺便把 public 网络也设置一下
# emacsclient ceph.conf
# cat ceph.conf
root@ceph1:~/my-cluster# cat ceph.conf
[global]
...
mon_initial_members = ceph1 ceph2 ceph3
public_network = 192.168.176.0/24
...
# 2. 把配置文件同步到其它节点
# ceph-deploy --overwrite-conf config push ceph1 ceph2 ceph3
# 3. 创建 monitor
# ceph-deploy mon create ceph2 ceph3
添加新 mds
mds 是 metadata service, 目前官方只推荐在生产环境中使用一个 mds. 因为 object 和 block storage 没有文件的概念, 不需要元数据, 所以 mds 只有在部署 CephFS 才有 意义.
# 1. 细节解释:
# 1) 把 ceph.conf 和 ceph.bootstrap-mds.keyring 复制到 ceph1:/etc/ceph 和
# /var/lib/ceph/bootstrap-mds/ceph.keyring
# 2) 创建 ceph1:/var/lib/ceph/mds/ceph-ceph1
# 3) ceph --cluster ceph --name client.bootstrap-mds \
# --keyring /var/lib/ceph/bootstrap-mds/ceph.keyring \
# auth get-or-create mds.ceph1 osd allow rwx mds allow mon allow profile mds \
# -o /var/lib/ceph/mds/ceph-ceph1/keyring
# 4) 启动 initctl emit ceph-mds cluster=ceph id=ceph1, 或者
# service ceph start mds.ceph1
# ceph-deploy mds create ceph1
作为文件系统使用
在一台安装了 ceph 客户端的机器上, 直接挂在
# mount -t ceph ceph1:6789:/ /mnt -o name=admin,secret=AQBhjqlSKBBTCxAAwchc9GauJ4+MPHz9hkV9Iw==
# df -h | grep mnt
192.168.176.30:6789:/ 297G 108M 297G 1% /mnt
作为块设备使用
在一台安装了 ceph 的机器上(或者可以用 ceph-deploy install machine-name 安装), 执行以下命令:
# modprobe rbd # 挂载 rbd 的内核模块
# rbd create --size 4096 test1 # 创建一个 4G 的 rbd 镜像
# 把 上面创建的 rbd 镜像映射到块设备 /dev/rbd/{poolname}/imagename , 这里为 /dev/rbd/rbd/test
# rbd map test1 --pool rbd
# 然后, 就可以像使用普通快设备一样使用这个块设备了(格式化,分区,直接给虚拟机使用), 例如
# mkfs.ext4 /dev/rbd/rbd/test1 # 格式化
# mount /dev/rbd/rbd/test1 /rbd
# df -h | grep rbd
/dev/rbd1 3.9G 8.0M 3.6G 1% /rbd




